lntroduction:
Here in this article we will discuss about how to improve performance in SQL server with table partitioning.
What is table partitioning?
SQL Server supports table partitioning. Table partition is way in which we separate the database table into different small parts (table). But still it gets treated as the single table by SQL layer.
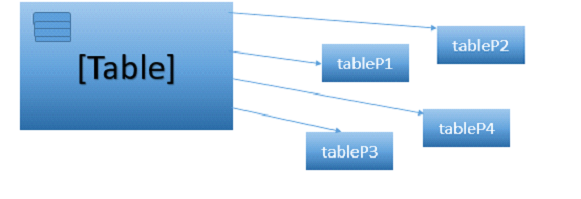
The partitioned table’s data is divided into units that can be spread across more than one filegroup in a database.
Why partition?
Consider a situation where a person wants to buy a new laptop. Just answer a simple question. Which will be faster for him? Searching desired laptop in a big shopping mall or a small shop. Definitely shop. Reason is simple – Shop is small, less items to scan and so quick to find the desired one.
Same applies in technical world. Partition will help to improve the performance of an application.
By implementing partition, we make queries run faster because based on condition query will be using the small table with small number of records instead of one big table. Scanning will be quick hence performance will be better.
We will the demonstration soon to make it clearer.
Initial setup
Now for our demo first let’s create a demo table as follows.
Create table Product (ProductId int primary key, ProductName varchar (20), Cost int, CreatedOn date)
As you can see Column ProductId is primary key in the table so by default clustered index get created on it.
Next let’s insert 10 million records inside it.
To insert 10 million record at a time I had written one code in SQL server as follows.
Declare @Year int=2000; Declare @UQNameSuffix int=1; Declare @Cost int=1; While (@Year <2010) begin Declare @Count int=1; While (@Count < 1000000) begin insert into Product values (‘Mobile’+cast(@UQNameSuffix as nvarchar(max)), @Cost ,Convert (datetime , CAST(@Year as nvarchar(max))+'/02/19')); set @UQNameSuffix =@UQNameSuffix +1; set @Count =@Count +1; end set @Year =@Year +1; set @Cost =@Cost +500; end
(This above code written to insert records in product table where each year contains appx. 100000 products.)
This will take time to execute 10 million insert record.
This code is just written for demo, you can use this if you want or else you can insert appx. 10 million record in any other way you like.
Demo 1 – Without partition.
Query 1
Select * from Product where CreatedOn='2001/2/19'
Executing above query for… we get the following output.
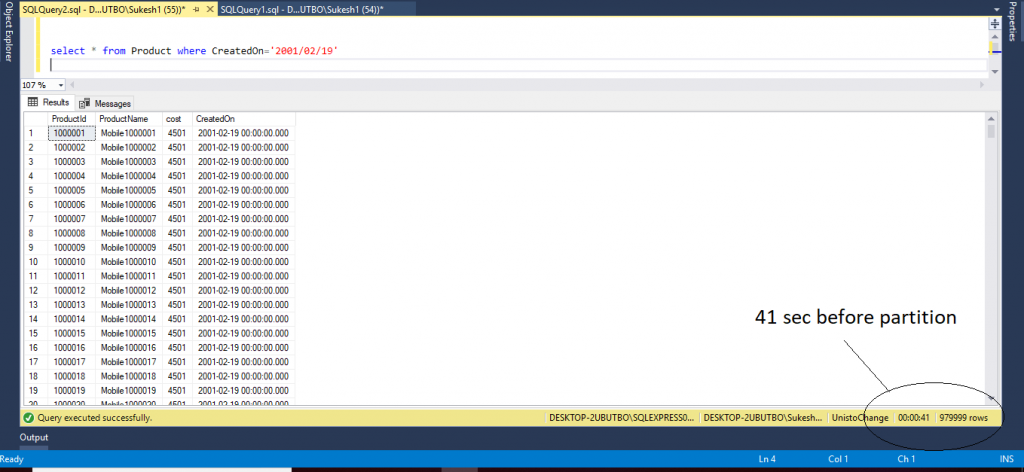
Time taken to execute above query is 41 sec
Query 2
select * from Product where cost>5000
Executing above query for… we get the following output.
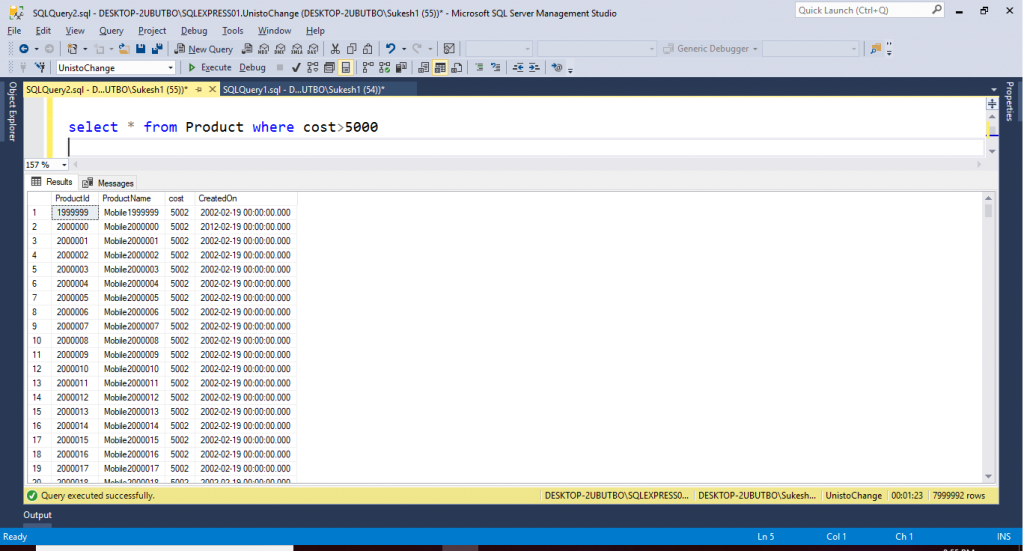
Time taken to execute above query is 01:23 sec
Query 3
Select CreatedOn from Product order by CreatedOn
Executing above query for… we get the following output.
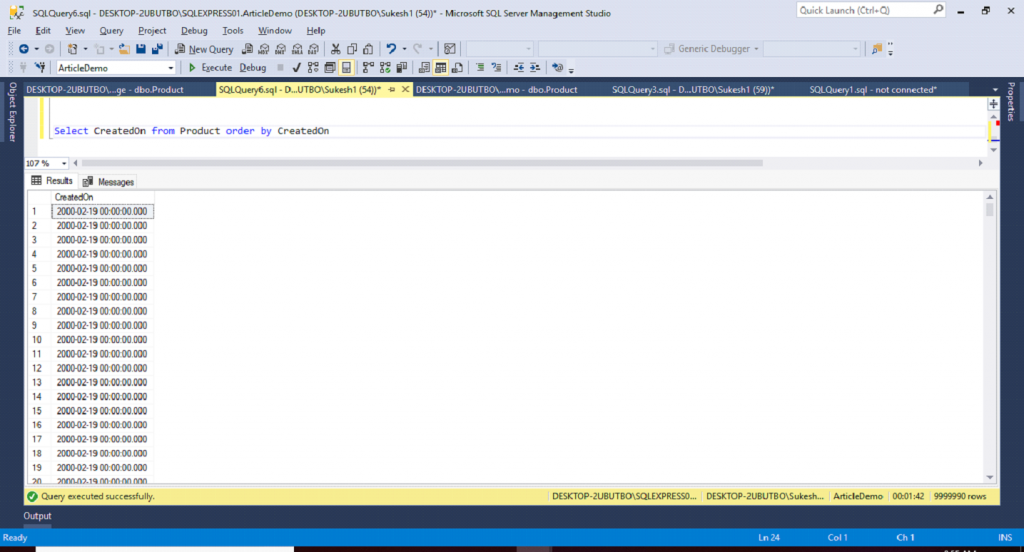
Time taken to execute above query is 01: 42 min
Like you saw. How much time these queries are taking and how slow the performance was. So to solve such problem we will do partitioning now.
Partitioning The Table
Now let’s partition above table based on “CreatedOn” and then let’s check the performance after.
Step 1 – Partition function
Execute following code for Creating new partition function.
Syntax
CREATE PARTITION FUNCTION partition_function_name (input_parameter_type) AS RANGE [LEFT | RIGHT] FOR VALUES [boundary_value [,..n ] ] ) [ ; ]
Example:–
CREATE PARTITION FUNCTION [CreatedOnDateRange] (datetime) AS RANGE
LEFT FOR VALUES ('2000-2-19','2001-2-19','2002-2-19','2003-2-19','2004-2-19','2005-
2-19','2006-2-19','2007-2-19','2008-2-19','2009-2-19')
Here partition function is created on CreatedOn column of table “Product” as “myCreatedOnDateRange”. Which is of datetime type.
Step 2 – Partition scheme
CREATE PARTITION SCHEME [DemoPartitionScheme] AS PARTITION [CreatedOnDateRange] TO ([PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY])
Here partition scheme is created as “DemoPartitionScheme” using the partition function “CreatedOnDateRange”.
Step 3 Non-Clustered index:
To get the partition executed properly this is the one of the important steps:
CREATE NONCLUSTERED INDEX [IX_Product_createdOn] ON Product ([CreatedOn] ASC) ON DemoPartitionScheme ([CreatedOn]);
Above query create the “Non Clustered index” on “CreatedOn” Colum of table ”Product’ in ascending order and also on partition scheme “DemoPartitionScheme”.
Step 4 See Partition:
Now let’s confirm that partition is created and for that let’s execute following query.
SELECT o.name objectname,i.name indexname, partition_id, partition_number, [rows] FROM sys.partitions p INNER JOIN sys.objects o ON o.object_id=p.object_id INNER JOIN sys.indexes i ON i.object_id=p.object_id and p.index_id=i.index_id WHERE o.name LIKE '%Product%'
Created Partition is as below:
See below image..
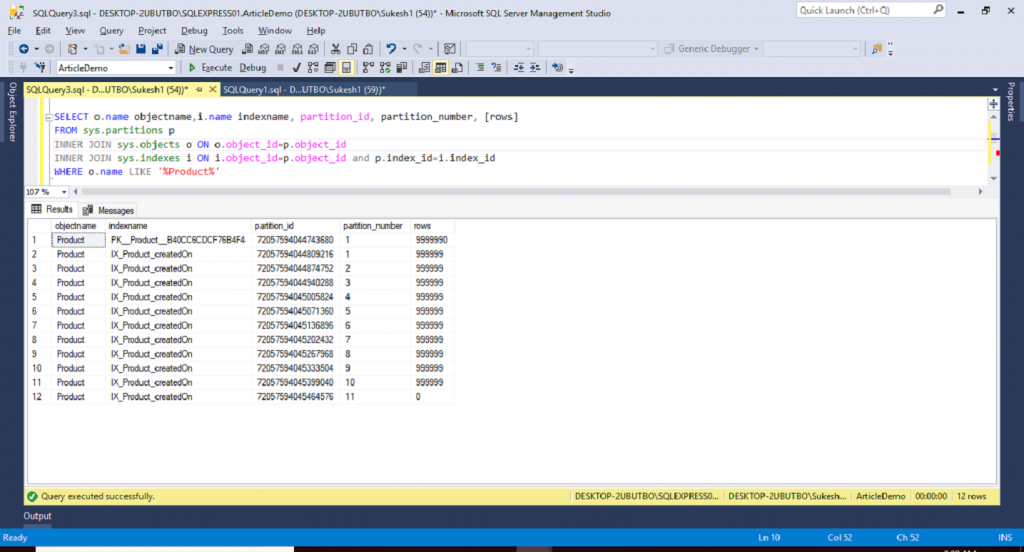
Demo 2 – With Partition.
Finally it’s time to test the queries and take the execution time for these
Query 1
Select * from Product where CreatedOn='2001/2/19'
Getting the following output after executing above query.
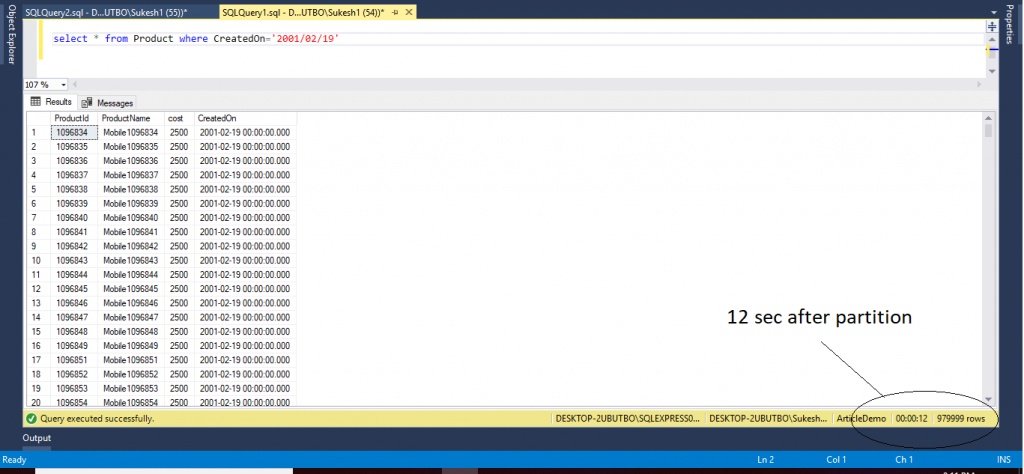
The execution time for this query is 12 sec .
Query 2
select * from Product where cost>5000
Getting the following output after executing above query.
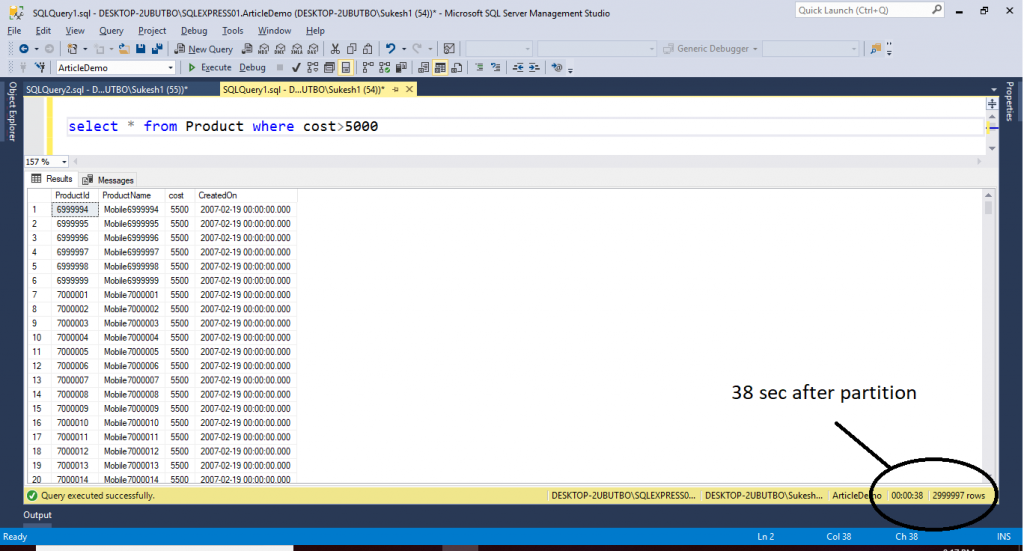
The execution time for this query is 38 sec
Query 3
Select * from Product order by CreatedOn
Getting the following output after executing above query.
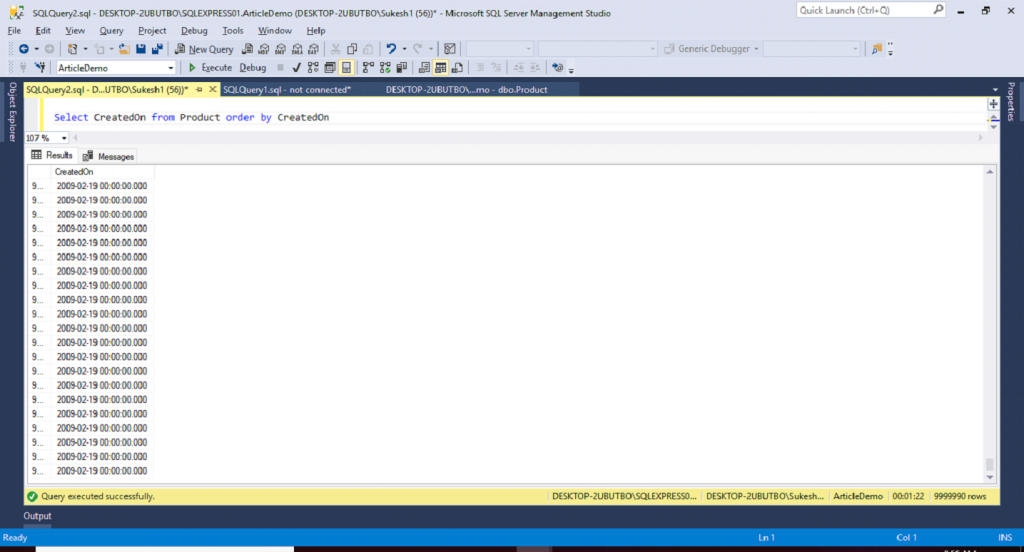
The execution time for this query is 01:22 min
Conclusion
As you can see after partition query performance got improved.
Please note, this feature is only available in the Enterprise edition of SQL Server.
Hope you enjoyed the article. Please drop your comments and don’t forget to share.

Nice article sir,
I will definitely apply in my project